LLM-grounded Diffusion: Enhancing Prompt Understanding of Text-to-Image Diffusion Models with Large Language Models
TL;DR: Text Prompt -> LLM -> Intermediate Representation (such as an image layout) -> Stable Diffusion -> Image.
LLM-grounded Diffusion
We equip diffusion models with enhanced spatial and common sense reasoning by using off-the-shelf frozen LLMs in a novel two-stage generation process.

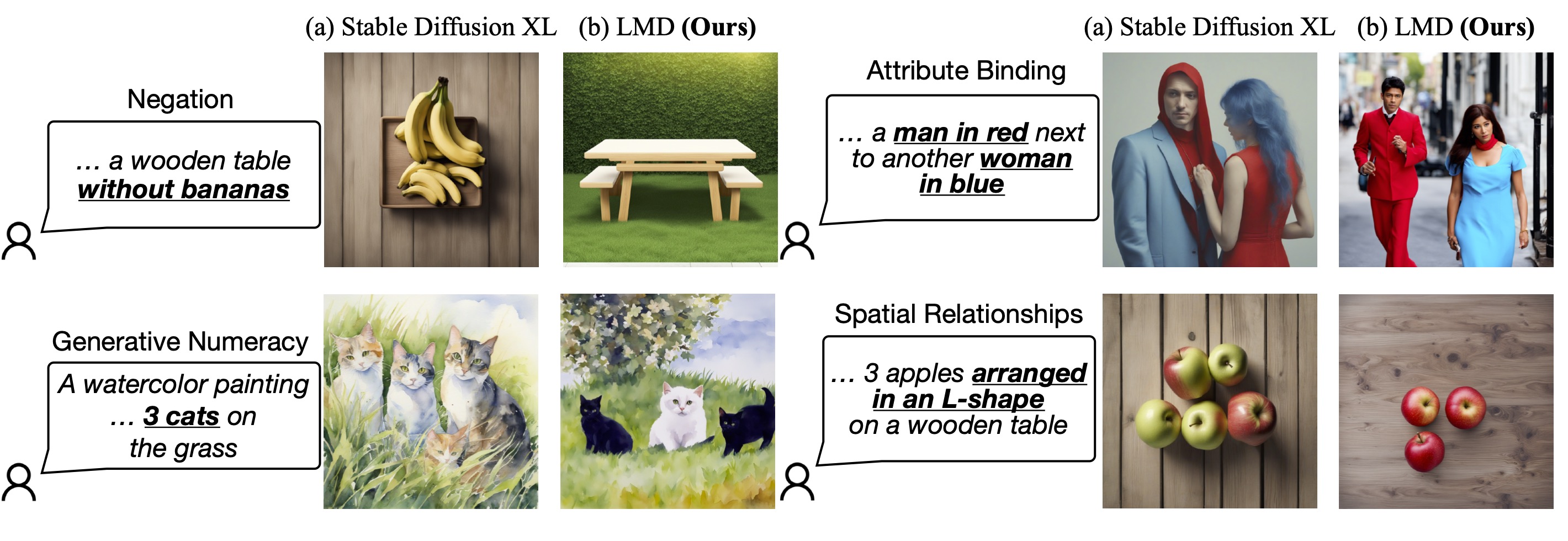
Visualizations
LLM-grounded Diffusion enhances the prompt understanding ability of text-to-image diffusion models.
Additional Capabilities
Incorporating an LLM for prompt understanding, LMD is able to perform dialog-based scene specification and generation from prompts in a language (Chinese in the example above) that the underlying diffusion model does not support.

Additional Capabilities: Multi-round Scene Specification


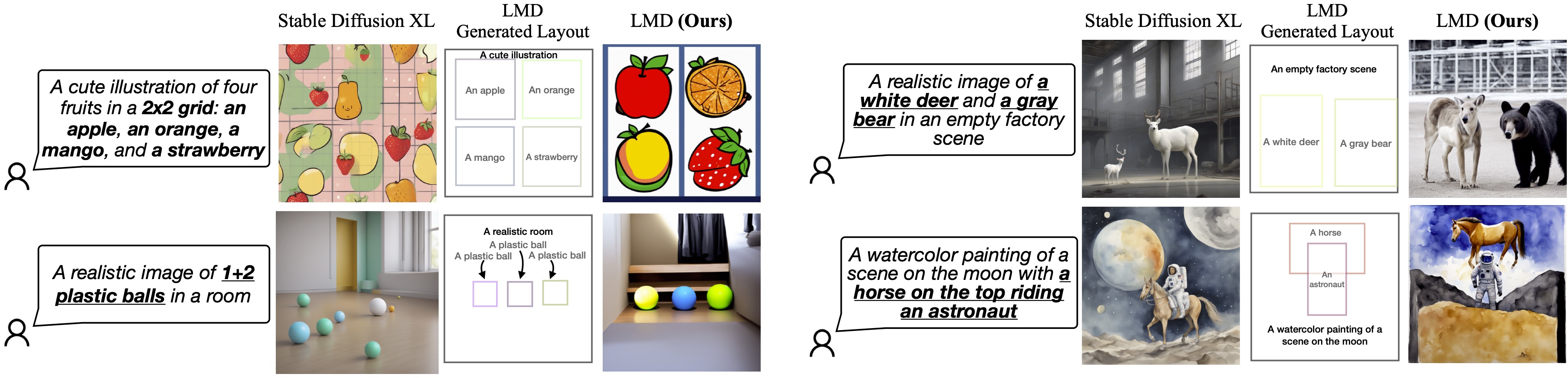
More Visualizations with LMD Layout
Citation
If you use this work or find it helpful, please consider citing:
@article{lian2023llmgrounded,
title={LLM-grounded Diffusion: Enhancing Prompt Understanding of Text-to-Image Diffusion Models with Large Language Models},
author={Lian, Long and Li, Boyi and Yala, Adam and Darrell, Trevor},
journal={arXiv preprint arXiv:2305.13655},
year={2023}
}